Part 4.5: Detour Hooking to Optimize SIMD Operations
Before diving into raw assembly, let’s take a step back. The function below is responsible for adding translation into the VP Matrix
In the previous post, I already pointed out how the game tends to over-engineer certain SIMD operations, performing a Vec4 × Matrix4x4 to reconstruct data that’s already directly available. Now it’s time to actually optimize those sequences.
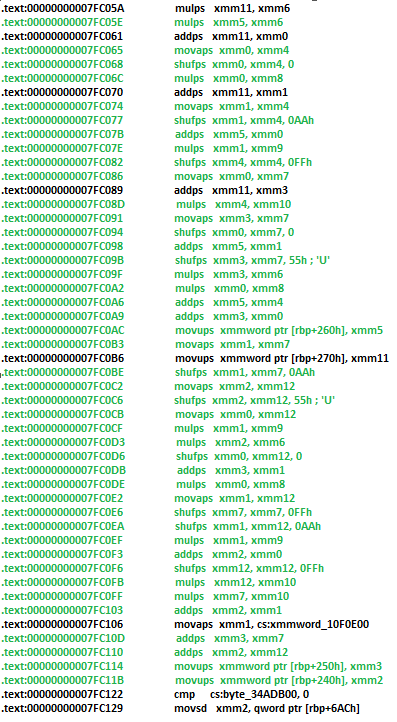
Take this section from sub_7FBF10, for example. At first glance, it looks like a massive chain of _mm_shuffle_ps, _mm_mul_ps, and _mm_add_ps calls:
But once you peel away all the unnecessary work, the end result collapses into something much cleaner:
This is just the largest redundancy in the function, not the only one.
For this function we will not be manually nopping SIMD instructions in assembly as that is going to take a lot of effort.
Instead we will use a method called detour hooking.
What is detour Hooking?
Just as the name suggests, detour hooking is a technique that forces a function to take a different route, you modify the machine code at any point of a function so that, when execution reaches it, control detours into your handler instead of following the original straight path. You usually do this by overwriting the first few bytes to a jump instruction. When that patched area executes, the CPU follows your detour.
Now in your detour you can implement your own custom code to do whatever you want it to, but keep in mind it is critical to preserve the original execution flow.
This means you must carefully manage the CPU’s state (registers, flags, and stack) to ensure the program continues to behave correctly after your code runs.
Common pitfalls include creating dead ends, returning incorrectly, corrupting registers, misalignment of stack (ABI convention RSP % 16 == 0 when a call is executed) etc.
Think of it this way:
you put a sign on the road that tells execution: “take this turn first,” but the car should always reach point B if you don’t want your game to crash.
Let me explain what we are going to be doing in a high level conceptually:
We’re looking at this function and it’s flooded with redundant SIMD instructions. Most of them contribute to the final ViewProjection result just in a very overengineered way that takes away performance (marginally). But scattered in between, there are still useful SIMD ops we need to keep:
Like:
This construction of v17 is important as this is the one that adds translation to the ViewProjection matrix. This function is scattered among the overengineered SIMD ops.
Here’s the approach:
- Match assembly to pseudocode: I’ll go through the disassembly and identify which SIMD instructions actually correspond to the math we care about. The rest is junk.
- Build a custom hook: In a code cave, I’ll re-implement only the useful SIMD ops in the correct order. This way, the essential calculations survive but the redundant ops get skipped.
- Redirect execution flow: At the entry point of the redundant section, I’ll overwrite the first 5 bytes with a jmp to my code cave.
- My custom logic runs (only useful SIMD).
- When done, I jmp back into the function after the redundant block, so execution continues.
This way, we don’t touch every instruction one by one, we just surgically detour into our cleaner version and rejoin the original code later skipping all redundant operations.
Text highlighted in green is redundant, Text highlighted in black are required calulations.
What we will be doing to circumvent it:

Now, before diving in
I won’t be showing how to find code caves here, that is out of scope for this write-up. Just know that in this case, I’ll be using a code cave that’s conveniently located close enough to our target function.
5 Byte Jmp hook vs 12 Byte Jmp hook
For the actual detour, I’ll be using the classic 5-byte jmp instruction.
- It’s made up of E9 (the jmp opcode) + a 4-byte signed relative offset.
- That offset can reach anywhere within ±2 GB of the jump site.
- This is why having a nearby code cave matters, you need the cave within that 2 GB window.
If you can’t rely on code caves (maybe there aren’t any close enough), then you can allocate your own memory with something like VirtualAllocEx. But in that case, the E9 relative jump won’t cut it anymore unless you allocate between ±2 GB.
That’s when you switch to a mov+jmp sequence:
mov rax, <absolute address>
jmp rax
Keep in mind this takes an absolute address where as the 5 byte jmp takes the offset from the instruction address to the location we need to go
It takes more bytes (usually 12 but depends on the register used), but it can jump anywhere in 64-bit address space. So:
- If you’ve got a cave nearby → use the 5-byte jmp.
- If not → allocate memory, use mov rax; jmp rax.
Either way, the result is the same
We will add this in our code-cave (Keep in mind a1 refers to rbp in this specific case):
- VP_NoTrans_Row0 holds its value inside xmm8
- VP_NoTrans_Row1 holds its value inside xmm6
- VP_NoTrans_Row2 holds its value inside xmm9
- v17 holds its value inside xmm11
All these were found using our previous method of IDA synchronize or just hover over the variable and IDA will display the register which holds it.
Writing our hook:
{ // Get the process ID DWORD procId = GetProcId(L"GhostOfTsushima.exe"); CHECK(procId); printf("ProcID: %d \n", procId); // Get the base Address baseAddr = GetModuleBaseAddress(procId, L"GhostOfTsushima.exe"); CHECK(baseAddr); printf("BaseAddr: %llx \n", baseAddr); // Open a handle to the process with full access hProcess = OpenProcess(PROCESS_ALL_ACCESS, false, procId); CHECK(hProcess); // Address of where we will place our jump uintptr_t patchAddr = baseAddr + patchOff; // Address of our code cave uintptr_t caveAddr = baseAddr + caveOff; // The address in the original function where execution should continue uintptr_t originalFuncContinue = baseAddr + 0x7FC122; // Calculate relative offset for E9 jmp (rel32) int64_t rel64 = (int64_t)caveAddr - ((int64_t)patchAddr + 5); int32_t rel32 = (int32_t)rel64; // 5-byte jmp instruction: E9 <rel32> BYTE jmpToCave[5] = { 0xE9 }; memcpy(jmpToCave + 1, &rel32, 4); // Overwrite target function bytes with our jump to code cave WriteProcessMemory(hProcess, (BYTE*)baseAddr + patchOff, jmpToCave, sizeof(jmpToCave), nullptr); BYTE shellCode[54] = { 0x44, 0x0F, 0x59, 0xDE, // mulps xmm11, xmm6 0x44, 0x0F, 0x58, 0xD8, // addps xmm11, xmm0 0x44, 0x0F, 0x58, 0xD9, // addps xmm11, xmm1 0x44, 0x0F, 0x58, 0xDB, // addps xmm11, xmm3 // Store final results 0x44, 0x0F, 0x11, 0x9D, 0x70, 0x02, 0x00, 0x00, // movups [rbp+0x270], xmm11 0x44, 0x0F, 0x11, 0x8D, 0x60, 0x02, 0x00, 0x00, // movups [rbp+0x260], xmm9 0x0F, 0x11, 0xB5, 0x50, 0x02, 0x00, 0x00, // movups [rbp+0x250], xmm6 0x44, 0x0F, 0x11, 0x85, 0x40, 0x02, 0x00, 0x00, // movups [rbp+0x240], xmm8 0x0F, 0x28, 0x0D, 0x65, 0x28, 0x8E, 0x00 // movaps xmm1, cs:xmmword_10F0E00 }; // Storage for our payload BYTE fullPatch[59]; size_t offset = 0; // Storing our entire payload memcpy(&fullPatch[offset], shellCode, sizeof(shellCode)); offset += sizeof(shellCode); // Calculate relative offset for jump back (from end of cave code) int64_t rel64_back = (int64_t)originalFuncContinue - ((int64_t)caveAddr + (int64_t)offset + 5); int32_t rel32_back = (int32_t)rel64_back; // Jump back: E9 <rel32> BYTE jmpBack[5] = { 0xE9 }; memcpy(jmpBack + 1, &rel32_back, 4); // Store our jump back to our payload memcpy(&fullPatch[offset], jmpBack, sizeof(jmpBack)); // Write full payload (our SIMD patch + jump back) into code cave WriteProcessMemory(hProcess, (BYTE*)baseAddr + caveOff, fullPatch, sizeof(fullPatch), nullptr); return 0; }
Code Explanation:
Process Setup:
We first locate the target game process and obtain a handle to the process for memory patching.
Detour Address Calculation:
We will calculate the exact location in the original function where we’ll hijack execution.
Forward Detour Creation:
We Replace the first 5 bytes at the target address with JMP
SIMD Optimization Payload:
Return Jump:
After our optimized SIMD code executes, we jump back to the original function. The game continues execution exactly where it would have been after the matrix construction, but with the over-engineered SIMD code removed.
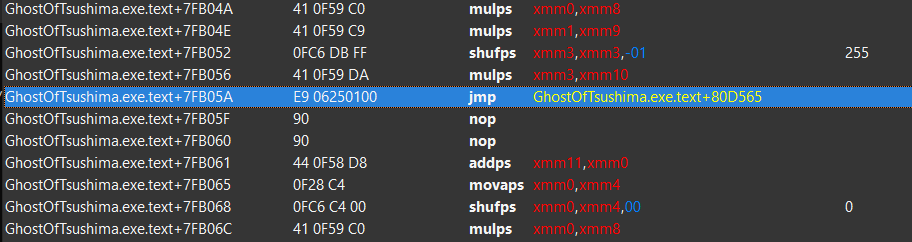
Executing our hook
Cheat Engine’s disassembly confirms that our hook was successfully written:
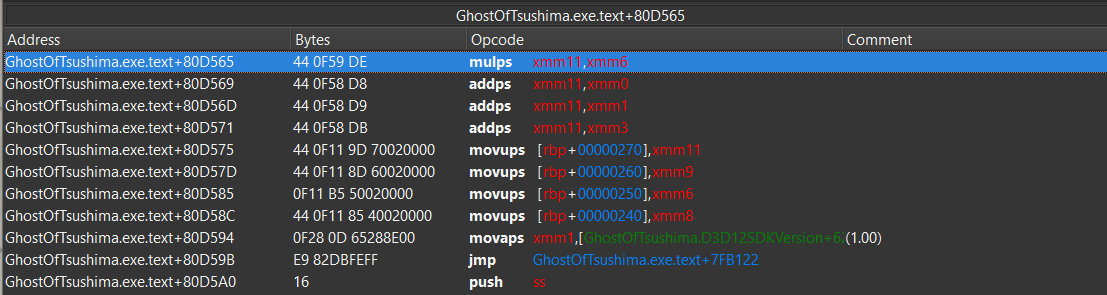
And our custom payload is seen in the code cave:
Observations in game and memory:
With the hook active, the game runs normally, no crashes, no artifacting. This validates our assumption that the stripped-out SIMD instructions were truly redundant and removing them only avoided a tiny bit of wasted work:
Matrix values remain identical with or without the hook

In-Game Observation

While not strictly redundant (the instructions still contribute to the final result), this sequence is clearly overengineered. The same output could be achieved with far fewer operations, which is why we treat them as ‘redundant’ for the purpose of optimization.
The performance gain here is so minuscule you’d honestly get more FPS by closing a calculator app running in the background. But it teaches a bigger lesson: systems don’t always do things the cleanest way, and compilers sure as hell aren’t infallible. Do not blindly trust compilers!