Part 4.1: Tracing the Matrix Construction Path
Tracing Functions Writing to The View-Projection Matrix
Lets start by observing which function writes to the View-Projection Matrix by clicking on the “Find out what writes this address” on the first element of the View-Projection Matrix.
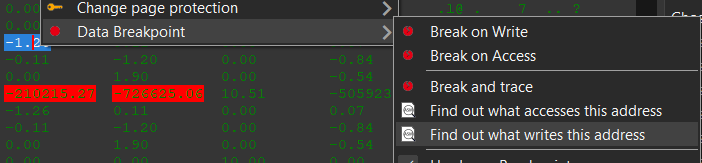
We have found 2 different functions that seem to write to this address.
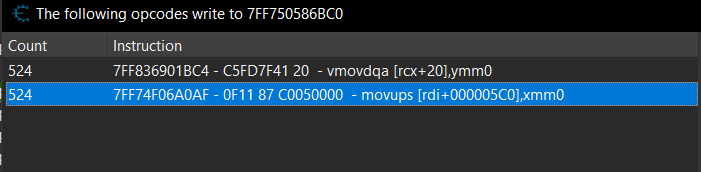
The first instruction seems to reference an address “VCRUNTIME140.memset+134:” and the second one references “GhostOfTsushima.exe+9AA0AF:”.
The second instruction intrigues me more so lets look at that one.
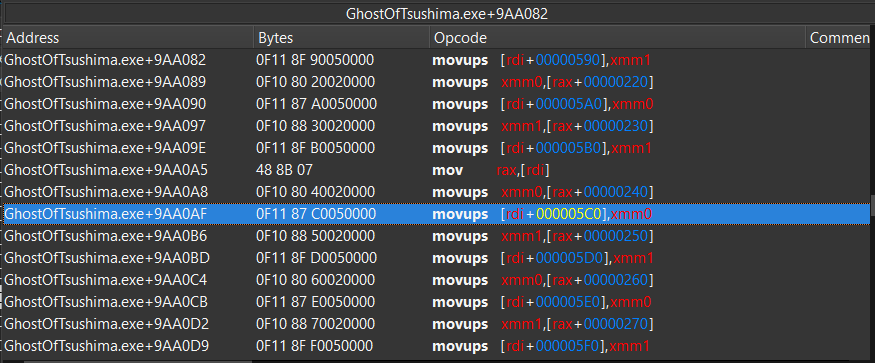
Here [rdi+0x5C0] is our static memory address of the view projection matrix and is getting written into by “xmm0”.
On x64, you’ll often see xmm0–xmm15 in the disassembly. These are 128-bit registers the CPU uses for SIMD (“Single Instruction, Multiple Data”) work, basically crunching multiple floats at once (4-32bit floats). Games use these for stuff like matrix math, vector transforms, and physics, because it’s faster than doing one number at a time.
Lets now see where “xmm0” gets its 4, 32bit float values from. In the instruction just above we see “xmm0” gets its value from
“movups xmm0,[rax+00000240]” which means [rax+00000240] would be where it seems to copy the values from.
lets see this entire function in IDA before moving further
lets “select current function” in cheat engine to get the function start address which is “GhostOfTsushima.exe+9AA040”.
Lets put this in IDA and see its pseudo-code.
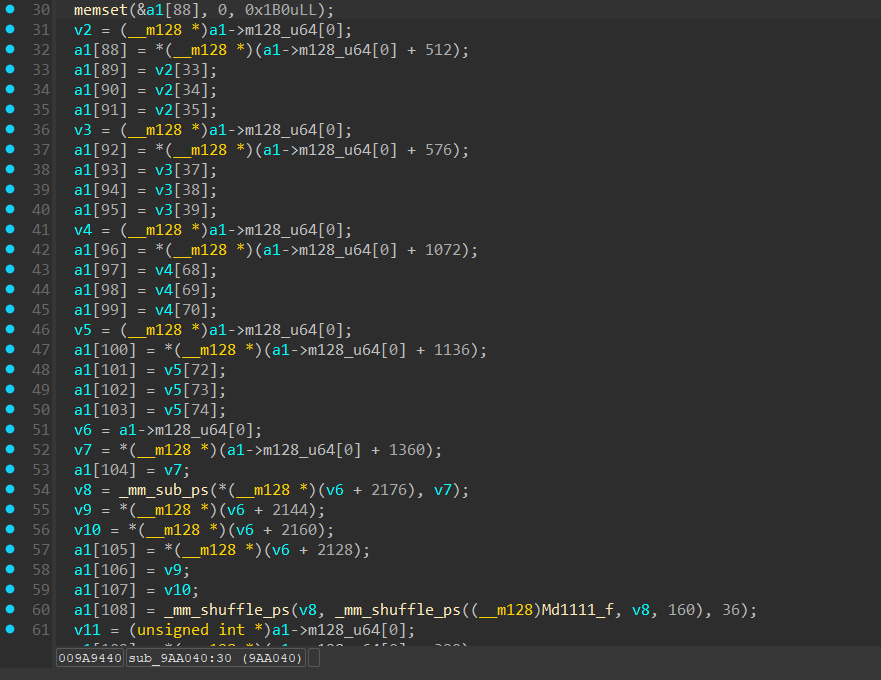
Don’t forget to rebase IDA to “0” before searching for the address in the function sub-view!
Alternatively, you can calculate the offset between the Cheat Engine base and the IDA base manually using a calculator.
While stepping through the function, I didn’t encounter many SIMD instructions like “mm_mul”, “mm_add_ps”, or “mm_shuffle_ps” (only a few). Instead, it appears that the function is primarily copying matrices from dynamic memory into this static location, possibly from a camera struct or a similar source.
Let’s now see what function writes to the dynamic address that its copying from - ([rax+0x240]):
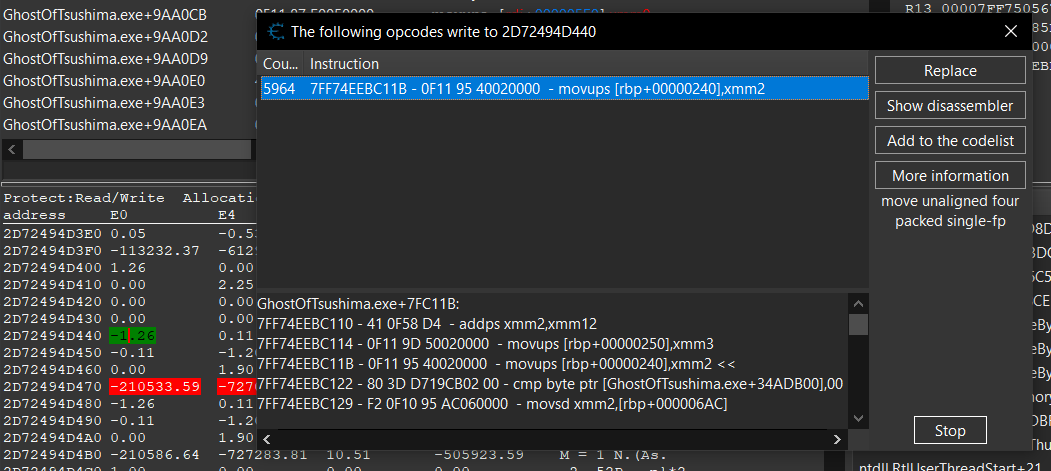
We can see one instruction reference “GhostOfTsushima.exe+7FC11B:”. Let’s select the current function and plug it into ida to see its pseudo code.
This is just a snippet of the start of the function.
Windows Calling Conventions (ABI)
On Windows x64, functions follow the Microsoft x64 calling convention. That means the first four parameters are passed in registers:
- RCX → first argument (a1)
- RDX → second argument (a2)
- R8 → third argument (a3)
- R9 → fourth argument (a4)
If there are more than four, the extras get pushed onto the stack. The return value usually ends up in RAX.
So if we see a function labeled with a1, a2, a3, those are just the values RCX, RDX, and R8 were holding when the function was called.
Breakpoint & Stacktrace
To figure out exactly what’s being passed in, we can set a breakpoint right at the start of the function in Cheat Engine, then check those registers.
That’ll give us a live snapshot of the arguments
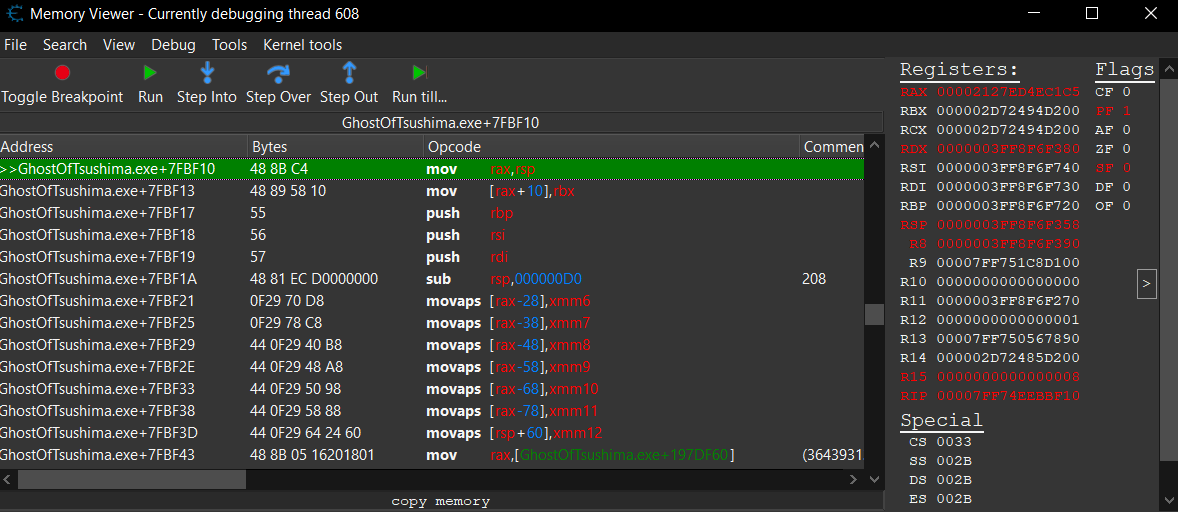
For now, the only argument of interest is a1, which corresponds to RCX. In this particular call, RCX = 0x2D72494D200.
I consider it “interesting” because of the following code snippet inside sub_7FBF10:
looking through the function we notice that it loads a single 4x4 matrix and a Vector4 near the start.
Let’s inspect the values at those offsets in memory.
At [a1 + 0x430], we find what appears to be a ViewProjection matrix without the translation component:

And at [a1 + 0x550], we find a Vector4 that corresponds to the camera position:

Since this function receives the view-projection matrix (without translation) as input, we can reasonably guess that the actual multiplication of the View and Projection matrices happens somewhere earlier in the call stack. this function isn’t building the full VP matrix from scratch, it’s taking an intermediate version and adding the translation part to make the final matrix the renderer uses.
We’ll break down this function in detail later, but for now, our goal is to trace the data flow further upstream to locate where this matrix begins its construction.
Let’s breakpoint at the start of the function and use the “stack trace” feature in cheat engine.
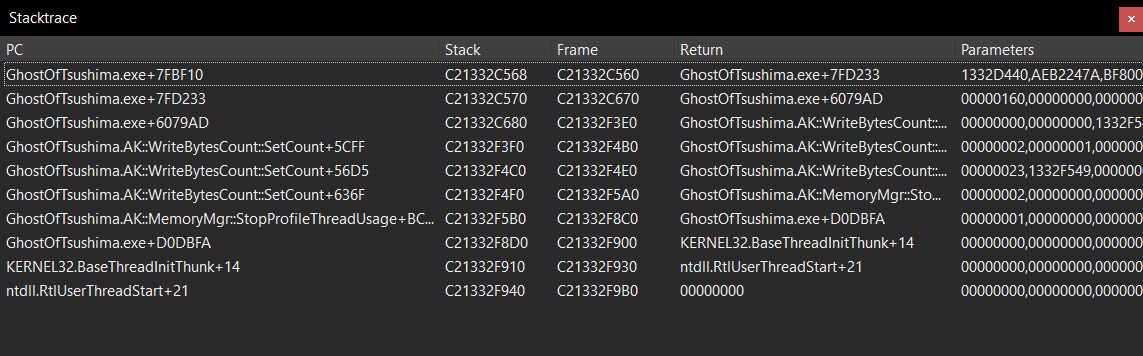
The first function is the function we are inside of.
The instruction at GhostOfTsushima.exe+7FD233 belongs to the function that called our current function (0x7FBF10).
We’ll grab the start address of the caller and plug it inside of IDA for further analysis.
IDA Code:
This function takes a single argument, probably a pointer to the camera structure.
Notably, it accesses two 4x4 matrices
[a1+0x200]:

This is just the Projection Matrix.
[a1+0x140]:

This is just the Camera World Matrix.
Throughout the function, we see use _mm_mul_ps, _mm_add_ps, and _mm_shuffle_ps popping up which is a indicator for SIMD matrix multiplication. The v16 array, which is made up of __m128 values, is gradually filled with the result of these operations, effectively forming a 4x4 matrix.
Why Not Just Invert It?
If you already have both the Projection (P) and the View-Projection (VP) matrices, you can simply compute the View-matrix (V) using Matrix algebra.
If the game uses the row-vector convention (common in DirectX), where the order is:
\(\begin{align}VP = V \times P\end{align}\)
Therefore, you can solve for V:
\(\begin{align} V = VP \times P^{-1}\end{align}\)
If the game uses the column-vector convention (common in OpenGL), where the order is:
\(\begin{align}VP = P \times V\end{align}\)
Then, you can solve for V:
\(\begin{align}V = P^{-1} \times VP\end{align}\)
But this lacks the insight into how the engine computes it internally, So we are going to do it the Hard Way.
Now that we have confirmed that this is probably the matrix construction function of the View-Projection matrix we can now start reversing its many SIMD instructions to see what exactly it does with the camera world matrix and projection matrix.