Part 3: Avalanche Engine (Matrix Multiplication Replaces Vector Addition)
Temporal Anti-Aliasing (TAA): Matrix Multiplication Replaces Vector Addition
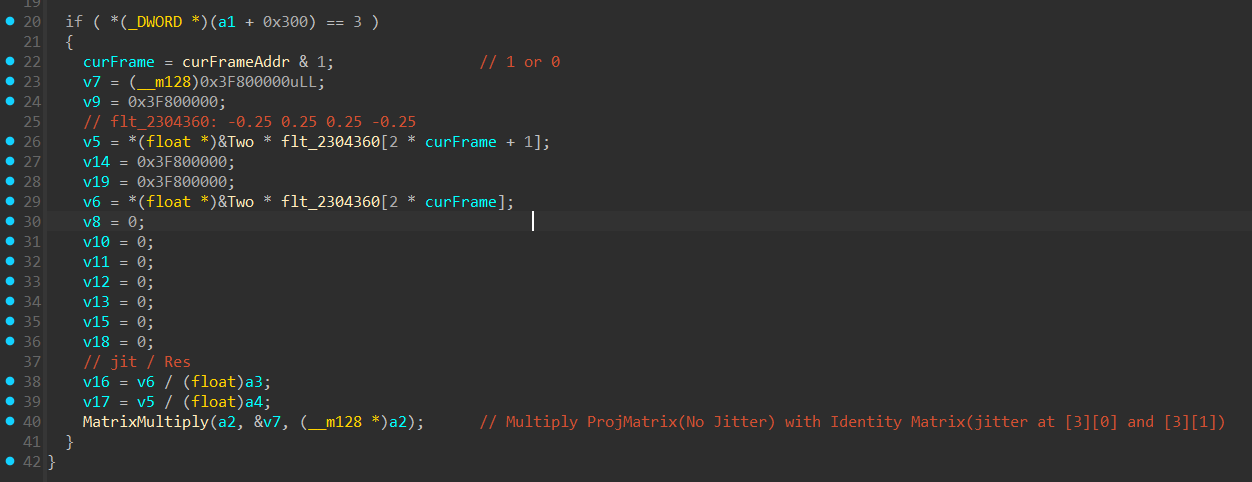
Here we see a very “Textbook” way of adding jitters to the projection matrix for SMAA_T2X in the Avalanche Engine.
The classic textbook way being:
\[\begin{bmatrix} x_{scale} & 0 & 0 & 0 \\ 0 & y_{scale} & 0 & 0 \\ 0 & 0 & \dfrac{z_{far}}{z_{far}-z_{near}} & 1 \\ 0 & 0 & -\dfrac{z_{near}z_{far}}{z_{far}-z_{near}} & 0 \end{bmatrix} \times \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ j_x & j_y & 0 & 1 \end{bmatrix} = \begin{bmatrix} x_{scale} & 0 & 0 & 0 \\ 0 & y_{scale} & 0 & 0 \\ j_x & j_y & \dfrac{z_{far}}{z_{far}-z_{near}} & 1 \\ 0 & 0 & -\dfrac{z_{near}z_{far}}{z_{far}-z_{near}} & 0 \end{bmatrix}\]This looks Clean when looking at the source code, but in a low-level CPU render loop, it is inefficient.
Probably would look something like this in C++:
Matrix4x4 jitterMatrix = Matrix4x4::Identity();
jitterMatrix.m[3][0] = jX;
jitterMatrix.m[3][1] = jY;
projMatrix = projMatrix * jitterMatrix;
Again: Clean C++ Code ≠ Clean Compiled Code
- First we need to construct an entire 4x4 Identity Matrix on the stack just to hold two float values.
- Then load the matrices as arguments into the function.
- Inside the function do stack allocation, set up security cookies, load registers etc.
- Multiply all rows to columns (repeated 4 times)
- Finally end the function by deallocating stack, verify the security cookie, loading result into memory and registers.
Note: Calculating
curFrame & 1, selecting jitters, scaling them down to sub-pixel space are all mathematically necessary steps and are not over-engineered.
The easier way to do it would be:
- Take the scaled down jitters.
- Take the 2nd Row (counting from 0) of the Projection Matrix and do a very simple
addps.
Example (where the jitters were already scaled down):
movaps xmm0, projMat_2 ; Load 2nd Row [0, 0, Z_scale, 1] movaps xmm1, jitter_Row ; [jitX, jitY, 0, 0] addps xmm0, xmm1 ; result: [jX, jY, Z_scale, 1]
That’s about a 120 instruction count drop to 3.