Part 2: Ghost Of Tsushima (Vector Extraction Through Multiplication)
Case 1: Vector Extraction Through Multiplication?
In Ghost of Tsushima while i was looking at how the View-Projection Matrix was being constructed i came across a common pattern where they do a full Row to column multiplication that could be replaced by a simple movaps instruction.
Take this Example (IDA pseudo code):
This is part of the construction of the View-Projection Matrix where the translation row of the matrix needed to be zeroed out (likely for skybox rendering). Multiply View with Projection only using directional vectors while zeroing out Translation.
The logic here is simply:
Step 1: Shuffle
- _mm_shuffle_ps(someRow1, someRow1, imm) selects one component of someRow1 and replicates it across all 4 slots of a new __m128.
- The different imm values pick different elements: 0x00-> picks element 0 (X) 0x55-> picks element 1 (Y) 0xAA-> picks element 2 (Z) 0xFF-> picks element 3 (W)
After shuffling, each __m128 looks like [X,X,X,X], [Y,Y,Y,Y], etc.
Step 2: Multiply with Projection Matrix
- Each shuffled vector is multiplied component-wise with a column of the projection matrix:
- This performs 4 parallel multiplications of the same row component with each element in the projection matrix column.
Step 3: Sum the results
- The _mm_add_ps calls sum all four products together:
- The result is a single row of the final View-Projection matrix.
The Problem:
The problem here is that xmmword_1138D10 has a value of: (0.0, 0.0, 0.0, 1.0).
Since the first three components are zero, those multiplications with ProjMat_0, ProjMat_1, and ProjMat_2 drop out. The only one left is the last one, where w = 1.0. Which means you’re just selecting the last row of the projection matrix (ProjMat_3).
So this whole instruction chain simplifies to basically 1 movaps instruction:
Case 2: Even More Vector Extraction Through Multiplication??
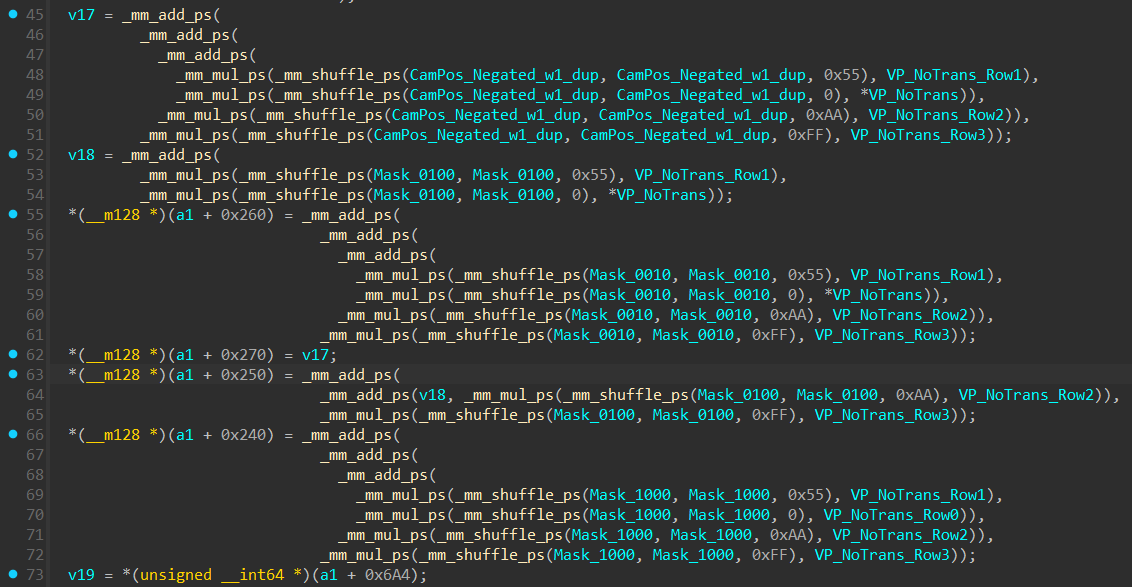
This is the later stage where translation is added back into the View-Projection Matrix where it was previously zeroed out, and it is done in a very confusing way.
This is the only Vector Multiplication that matters, the one where it’s adding back the translation into the VP matrix.
Here is the biggest reduction:
This is just extracting the values stored in the VP rows using Masks.
Mask_1000 is (1, 0, 0, 0) Mask_0100 is (0, 1, 0, 0) Mask_0010 is (0, 0, 1, 0)
Multiplying a unit vector by a matrix simply extracts the corresponding row. The original code was laboriously performing this extraction manually for each axis:
- The calculation for 0x240 used Mask_1000 to extract Row0.
- The calculation for 0x250 used Mask_0100 to extract Row1.
- The calculation for 0x260 used Mask_0010 to extract Row2.
So it just collapses into 3 movaps instructions and 1 vector multiplication.
Again: I was not looking specifically for over-engineered code, this just stood out a lot.
I have also optimized this on my previous blog in assembly (for fun):
Reversing The ViewProjection Matrix - Part 4.5: Detour Hooking to Optimize SIMD Operations