Part 1: Dunia Engine (Redundancy And Over-Engineering)
Intro:
Before I delve in this I need to get a few things out of the way ⚠️:
To be completely clear: I did not go looking for this. I was simply reversing engines to study how they constructed their fundamental Transformation matrices and handled temporal jitter logic. But reading a core rendering function and seeing such avoidable overhead practically hits you in the face. You are not looking at unoptimized code but codebase culture.
Nowww, the functions we are going to dissect are only run a few times per frame, so it really doesn’t matter if we optimize it or not. But it raises an uncomfortable question: If such optimizations are not even considered on these important rendering pathways then what other functions are overlooked? does such culture infest every other system in the engine?
This is a symptom of “Profiler-Invisible-Waste”; it is a classic case of missing the forest for the trees. You will never find this issue through a profiler, the culture is ingrained in every function. This leads to “Death By a Thousand Cuts”.
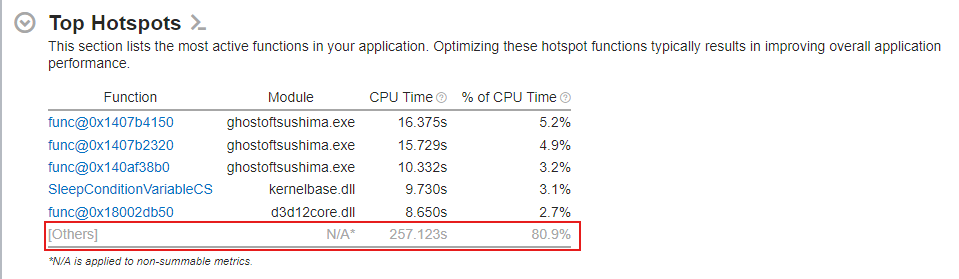
Look at this VTune capture. The top hotspots barely break 5% of the CPU time each. But look at the red box: 80.9% of the execution time is buried in [Others]. Profilers are designed to find massive, isolated bottlenecks.
But if your entire codebase is built on over-engineered abstractions and bloated generic math wrappers, the baseline execution cost of every function is raised. You don’t get a few obvious performance spikes; you get a uniformly elevated floor.
That 80% block is exactly where those “thousand cuts” are hiding.
We will go over 3 separate game engines:
- Dunia Engine (Far Cry Series)
- Sucker Punch Studios Proprietary Engine (Ghost of Tsushima)
- Avalanche Engine (Just Cause Series)
And all 3 have one common “Antagonist”.
Basic Outline:
Redundancy and Over-Engineering:
First we will go over all of the Redundant and Over-Engineered code which exists in the engine. Then explain why it is Redundant/Over-Engineered and how it could have been written. I will show Difference in instruction count side-by-side (Original vs Hand Written Assembly).
We will also come up with theories on why this happens, Specifically on the concept “Clean C++ Code ≠ Clean Compiled Code”
Compatibility, Legacy and Readable Code
The Compatibility Tax: Not Wrong, Just Capped. In my next write-up we will look at the realities of AAA game development. Not all of this is the result of developers blindly trusting compilers. I will show sections of the engine where the code could theoretically run way faster (with some functions reaching 5× speedups) due to new advancements in processor architecture, but couldn’t be fully utilized because the engine must maintain compatibility with a wide range of hardware.
This whole write-up is just food for thought, a question really: “What is the performace tax for such abstractions?”
Case 1: Y-up To Z-up Over-Engineering (Dunia Engine)
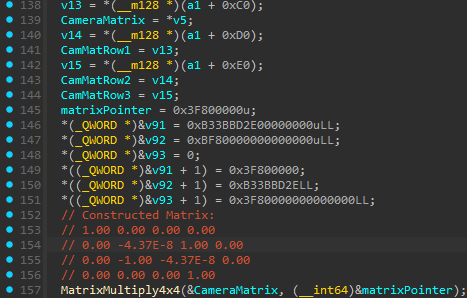
This is doing a Coordinate Space Conversion in a very “Textbooky” way. They first construct a Matrix:
\[M = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & -4.37 \times 10^{-8} & 1 & 0 \\ 0 & -1 & -4.37 \times 10^{-8} & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}\]on the stack, probably using some function like Matrix::CreateRotationX(-PI / 2)
So it actually constructed:
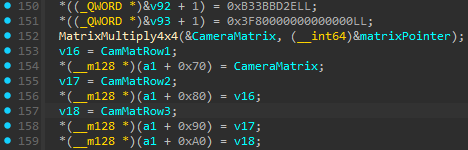
\[\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & \cos(-90^\circ) & -\sin(-90^\circ) & 0 \\ 0 & \sin(-90^\circ) & \cos(-90^\circ) & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}\]Then pass the arguments to MatrixMultiply4x4(&CameraMatrix, (__int64)&matrixPointer);
Where the logic for the function is a2 × a1 = a1
Let’s put a breakpoint in the multiply call to see exactly what happens after this multiplication:
I am looking exactly “north” in-game when breakpointing
Before:
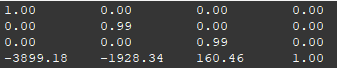
After:

So, take the up vector, negate it and put it on row 2, then take the forward vector and put it on row 1.
Let me put into perspective how many assembly instructions were executed just to do this:
Pseudo code of MatrixMultiply4x4:
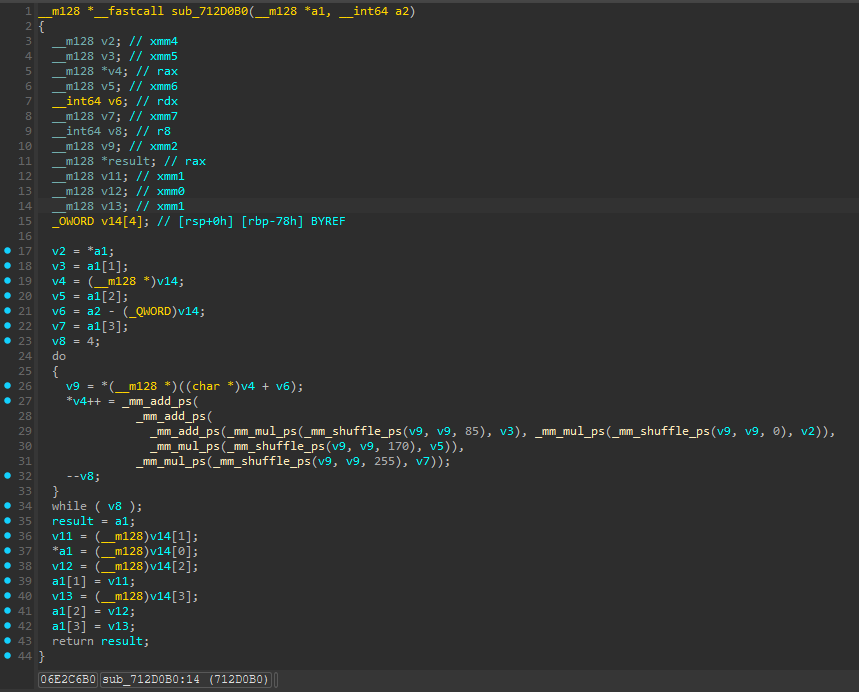
All this for a very simple coordinate space conversion?
We could simply shuffle it ourself using movaps to swizzle the vectors then simply use xorps with mask 0x80000000 for negation! Let’s try:
It seems to be storing the result of the multiply into the camera structure, we could simply change how they store the rows in the camera structure. The multiplied result will not be used by the current function and will be simply deallocated as it’s constructed on the stack so we only care about what’s in the camera structure.
So now take the up vector negate it and put it on row2, then take forward vector and put it on row1.
Counting rows from 0!
For this to work we simply change v16 = CamMatRow1; to v16 = CamMatRow2;
and
v17 = CamMatRow2; to v17 = CamMatRow1;
This simple change would not add more assembly instructions, we are simply modifying existing instructions.
then simply xorps v17, 0x80000000 to negate the bits.
And we are done!
So the total difference in instruction count is 133 to 1! where we only added one new instruction:
xorps v17, 0x80000000
while completely nuking all other instructions i have shown above.
To be clear: the instructions moving the vectors into the camera structure aren’t redundant. They are a sunk cost that has to execute regardless, thus i did not include those instructions in the assembly showcase. The only net-new instruction required to achieve the coordinate conversion is a single xorps, thus i am calling it a 133 to 1 instruction count decrease.
Instruction Count Visualized:
; 1. Load Camera Matrix
movaps xmm0, xmmword ptr [rdi]
movaps xmm1, xmmword ptr [rbx+0C0h]
movaps [rsp+1A0h+CameraMatrix], xmm0
movaps xmm0, xmmword ptr [rbx+0D0h]
movaps [rsp+1A0h+CamMatRow1], xmm1
movaps xmm1, xmmword ptr [rbx+0E0h]
movaps [rsp+1A0h+CamMatRow2], xmm0
movaps [rsp+1A0h+CamMatRow3], xmm1
; 2. Construct Identity/Swizzle Matrix
mov qword ptr [rsp+1A0h+matrixPointer], 3F800000h
mov dword ptr [rbp+0A0h+var_120], 0
mov dword ptr [rbp+0A0h+var_110], 0
mov qword ptr [rbp+0A0h+var_100], 0
mov dword ptr [rbp+0A0h+var_120+4], 0B33BBD2Eh
mov dword ptr [rbp+0A0h+var_110+4], 0BF800000h
mov qword ptr [rsp+1A0h+matrixPointer+8], 0
mov qword ptr [rbp+0A0h+var_120+8], 3F800000h
mov dword ptr [rbp+0A0h+var_110+8], 0B33BBD2Eh
mov dword ptr [rbp+0A0h+var_100+8], 0
mov dword ptr [rbp+0A0h+var_110+0Ch], 0
mov dword ptr [rbp+0A0h+var_100+0Ch], 3F800000h
; 3. Setup Arguments & Call MatrixMultiply4x4
lea rdx, [rsp+1A0h+matrixPointer]
lea rcx, [rsp+1A0h+CameraMatrix]
call MatrixMultiply4x4
; 4. Inside Function: ABI Overhead
sub rsp, 78h
movaps [rsp+78h+var_18], xmm6
movaps [rsp+78h+var_28], xmm7
mov rax, cs:__security_cookie
xor rax, rsp
mov [rsp+78h+var_38], rax
movaps xmm4, xmmword ptr [rcx]
lea r8, [rsp+78h+var_78]
movaps xmm5, xmmword ptr [rcx+10h]
lea rax, [rsp+78h+var_78]
movaps xmm6, xmmword ptr [rcx+20h]
sub rdx, r8
movaps xmm7, xmmword ptr [rcx+30h]
mov r8d, 4
; 5. SIMD Unrolled Loop (x4 Iterations)
; --- iteration 1 ---
movaps xmm2, xmmword ptr [rdx+rax]
movaps xmm3, xmm2
movaps xmm0, xmm2
shufps xmm3, xmm2, 55h
movaps xmm1, xmm2
shufps xmm0, xmm2, 0
mulps xmm3, xmm5
shufps xmm1, xmm2, 0AAh
mulps xmm0, xmm4
mulps xmm1, xmm6
shufps xmm2, xmm2, 0FFh
addps xmm3, xmm0
mulps xmm2, xmm7
addps xmm3, xmm1
addps xmm3, xmm2
movaps xmmword ptr [rax], xmm3
add rax, 10h
sub r8, 1
jnz short loc_712D0F0
; --- iteration 2 ---
movaps xmm2, xmmword ptr [rdx+rax]
movaps xmm3, xmm2
movaps xmm0, xmm2
shufps xmm3, xmm2, 55h
movaps xmm1, xmm2
shufps xmm0, xmm2, 0
mulps xmm3, xmm5
shufps xmm1, xmm2, 0AAh
mulps xmm0, xmm4
mulps xmm1, xmm6
shufps xmm2, xmm2, 0FFh
addps xmm3, xmm0
mulps xmm2, xmm7
addps xmm3, xmm1
addps xmm3, xmm2
movaps xmmword ptr [rax], xmm3
add rax, 10h
sub r8, 1
jnz short loc_712D0F0
; --- iteration 3 ---
movaps xmm2, xmmword ptr [rdx+rax]
movaps xmm3, xmm2
movaps xmm0, xmm2
shufps xmm3, xmm2, 55h
movaps xmm1, xmm2
shufps xmm0, xmm2, 0
mulps xmm3, xmm5
shufps xmm1, xmm2, 0AAh
mulps xmm0, xmm4
mulps xmm1, xmm6
shufps xmm2, xmm2, 0FFh
addps xmm3, xmm0
mulps xmm2, xmm7
addps xmm3, xmm1
addps xmm3, xmm2
movaps xmmword ptr [rax], xmm3
add rax, 10h
sub r8, 1
jnz short loc_712D0F0
; --- iteration 4 ---
movaps xmm2, xmmword ptr [rdx+rax]
movaps xmm3, xmm2
movaps xmm0, xmm2
shufps xmm3, xmm2, 55h
movaps xmm1, xmm2
shufps xmm0, xmm2, 0
mulps xmm3, xmm5
shufps xmm1, xmm2, 0AAh
mulps xmm0, xmm4
mulps xmm1, xmm6
shufps xmm2, xmm2, 0FFh
addps xmm3, xmm0
mulps xmm2, xmm7
addps xmm3, xmm1
addps xmm3, xmm2
movaps xmmword ptr [rax], xmm3
add rax, 10h
sub r8, 1
jnz short loc_712D0F0
; 6. Deallocate & Return
movaps xmm0, [rsp+78h+var_78]
mov rax, rcx
movaps xmm1, [rsp+78h+var_68]
movaps xmmword ptr [rcx], xmm0
movaps xmm0, [rsp+78h+var_58]
movaps xmmword ptr [rcx+10h], xmm1
movaps xmm1, [rsp+78h+var_48]
movaps xmmword ptr [rcx+20h], xmm0
movaps xmmword ptr [rcx+30h], xmm1
mov rcx, [rsp+78h+var_38]
xor rcx, rsp
call j___security_check_cookie
movaps xmm6, [rsp+78h+var_18]
movaps xmm7, [rsp+78h+var_28]
add rsp, 78h
retn; Just swap the pointers and flip the sign bit
movaps v16, CamMatRow2
movaps v17, CamMatRow1
xorps v17, 0x80000000You might say it’s for readability or that it makes it easier to modify the coordinate conversion later. But for a programmer who grasps the underlying math, the intent behind swapping rows and flipping a sign is perfectly clear especially since we can express the exact same logic cleanly using SSE intrinsics in C++. Memorizing textbook formulas is fine, but if you don’t understand the actual spatial intent behind them you’re just pattern-matching
Case 2: Atanf just to get back FovX:
I’ve already talked about this here Reversing The Prespective Projection Matrix (Part 5.1) but want to shine light on this in more detail.
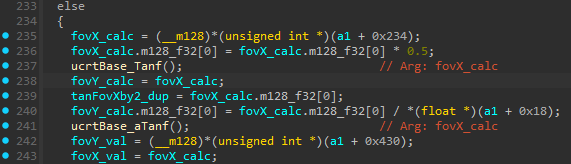
The arguments for tanf and atanf are not given but i have read the assembly (which is loaded into xmm0 just before call) and written the arguments on the right.
Let’s start with this block
Using CE for dynamic analysis we can see that (a1 + 0x234) is FovX in radians
So it basically loads FovX in radians into “fovX_calc” then immediately divide it by 2 so now “fovX_calc” holds the value fovX/2.
Next Tanf() is called with arg = fovX_calc so fovX_calc currently holds the value tan(fovX/2)
Next the engine does a lot of calculations using tan(fovX/2), then the engine decides it actually needs the value of fovX back so it does it in an ingenious way!
The fovX_calc variable is never used again in the function
we all know the identity arctan(tan(x)) = x holds if and only if x lies strictly inside (−90°, 90°), the identity holds without exception. FovX can only have a value from 60 to 120 degrees in-game. Since we divided it by 2, the angle is between 30 and 60 degrees (well within the -π/2 to π/2 principal bounds of arctan)
The codebase culture accepts:
\(x = 2 \cdot \arctan\!\left(\tan\!\left(\frac{x}{2}\right)\right)\)
as a valid way to move data from point A to point B.
So just to get back the raw fovX they call atanf then multiply it by 2. It could have been easily avoided by simply loading it from the camera structure again without it taking anywhere near a full IEEE 754 atanf calculation cycles since it’s certainly loaded in the L1 cache or alternatively just storing it to another unused xmm register to save it
Keep in mind this is not using the formula to find FovY which is:
\(FOV_Y = 2 \cdot \tan^{-1}\!\left(\frac{\tan\!\left(\frac{FOV_X}{2}\right)}{A}\right)\)
There is no Aspect Ratio used here.
We cant exactly tell how many cycles atanf() has used. It can range from 30 to 150 depending on your CPU architecture.
One meaningless atanf() on a function that only runs a few times per frame? That’s negligible.
Multiple redundant atanf() calls scattered across the codebase? That’s adding up.
Multiple redundant atanf, tanf, sinf, cosf, matrix multiply, matrix inversions, dot products, cross products etc etc..? That’s huge.
The Point:
The point here isn’t, “OmG tHeY uSeD a FuLl iEeE 754 bIt PeRfEct aTanf() CaLL jUsT tO gEt BaCk fovX!”
Let’s be real: doing that in a function that only runs a few times per frame doesn’t actually cost much, whether it’s an atanf call or a MatrixMultiply4x4.
The real point is: “Does it stop here?”, “Does this practice not carry over to all other systems?”
It does. This same over-engineering and “clean C++” bleeds into entirely different generic functions across the codebase. We’re talking atanf, tanf, sinf, cosf, 1/sqrtf, normalization, matrix multiply, matrix inversions, dot products, cross products, and honestly a whole, whole lot more.
And it’s probably not just math libraries being used like this.
This is the exact definition of “Death by a Thousand Cuts”. The Codebase ensures you’re bleeding from everywhere.
Now that you know the point of this blog i will continue with Ghost of Tsushima and the Avalanche Engine.