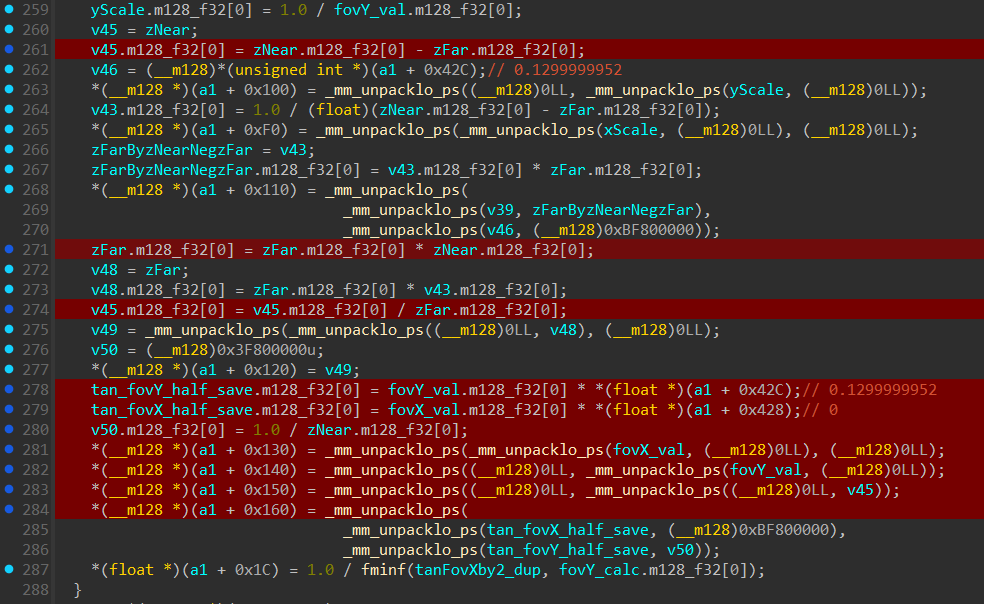
Now for the final matrix getting constructed by the else block!
I have isolated all lines relating to the construction of the Inverse Projection Matrix:
Let’s start with row 0.
Row 0:
*(__m128 *)(a1 + 0x130) = _mm_unpacklo_ps(_mm_unpacklo_ps(fovX_val, (__m128)0LL), (__m128)0LL);
Where the last value for fovX_val was:
19 fovX_val.m128_f32[0] = fovX_val.m128_f32[0] * 0.5;
20 ucrtBase_Tanf();
so Row 0 = [tan(fovX/2), 0, 0, 0]
Row 1:
*(__m128 *)(a1 + 0x140) = _mm_unpacklo_ps((__m128)0LL, _mm_unpacklo_ps(fovY_val, (__m128)0LL));
Where the last value for fovY_val was:
22 fovY_val.m128_f32[0] = fovY_val.m128_f32[0] * 0.5;
25 ucrtBase_Tanf();
so Row 1 = [0, tan(fovY/2), 0, 0]
Row 2:
*(__m128 *)(a1 + 0x150) = _mm_unpacklo_ps((__m128)0LL, _mm_unpacklo_ps((__m128)0LL, v45));
“v45” comes from:
33 v45 = zNear;
34 v45.m128_f32[0] = zNear.m128_f32[0] - zFar.m128_f32[0];
42 zFar.m128_f32[0] = zFar.m128_f32[0] * zNear.m128_f32[0];
45 v45.m128_f32[0] = v45.m128_f32[0] / zFar.m128_f32[0];
I don’t feel like this needs explaining, all very self explanatory:
\[\large v_{45} = \frac{z_{near} - z_{far}}{z_{far} \cdot z_{near}}\]
Final Unpack: [0, 0, 0, (near - far) / (far * near)]
Row 3:
*(__m128 *)(a1 + 0x160) = _mm_unpacklo_ps(
_mm_unpacklo_ps(tan_fovX_half_save, (__m128)0xBF800000),
_mm_unpacklo_ps(tan_fovY_half_save, v50));
We already know “tan_fovX_half_save” is tan(fovX/2) which just before get’s multiplied with “0” while “tan_fovY_half_save” which previously had the value of “tan(fovY/2)” is multiplied
with our anomaly “0.1299999952”.
These calculations are done in these lines:
49 tan_fovY_half_save.m128_f32[0] = fovY_val.m128_f32[0] * *(float *)(a1 + 0x42C);
50 tan_fovX_half_save.m128_f32[0] = fovX_val.m128_f32[0] * *(float *)(a1 + 0x428);
Next, “v50” is simply:
51 v50.m128_f32[0] = 1.0 / zNear.m128_f32[0];
and “0xBF800000” is “-1”
Final Unpack: [0, tan(fovY/2)*0.13, -1, 1/near]
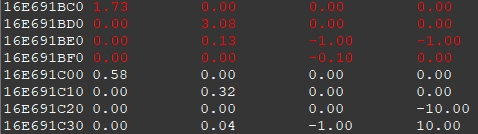
Final Layout:
\[\begin{bmatrix}
\tan(fovX/2) & 0 & 0 & 0 \\
0 & \tan(fovY/2) & 0 & 0 \\
0 & 0 & 0 & \frac{near - far}{far \cdot near} \\
0 & \tan(fovY/2) \cdot 0.13 & -1 & \frac{1}{near}
\end{bmatrix}\]
This matches what we have seen previously in cheat engine’s memory viewer!
Reversing Insight
The engine is doing something incredibly smart here. Instead of relying on a generic 4x4 matrix inversion algorithm (like Cramer’s rule) which requires a heavy, separate function call
and eats up valuable CPU cycles. It performs a heavily optimized algebraic “fast inverse” inline. Because a projection matrix has so many known zeroes, the developers hardcoded the exact
algebraic inverse right into the function.
Bit of a side track - Initially, when staring at this block, I didn’t even realize I was looking at an Inverse Projection Matrix. In hindsight it’s very obviously an inverse projection.
We unconsciously look for standard math library calls (like a MatrixInversefunction), so when it’s just raw, inline floating-point math, it’s easy to miss.
So how do you prove a hunch when the code is ambiguous?
The Scientific Method of Hypothesis ➔ Observation ➔ Conclusion!
- Hypothesis: This weird block of inline math is manually constructing the Inverse Projection Matrix.
- Observation: I dumped the originally constructed Projection Matrix directly from memory and ran it through a standard matrix inversion script on my own. I then compared my calculated output against the values the engine was generating in this second matrix.
- Conclusion: The floats lined up exactly. Hypothesis confirmed! we have found the Inverse Projection.
The Full Picture:
1 else
2 {
3 fovX_calc = (__m128)*(unsigned int *)(a1 + 0x234);
4 fovX_calc.m128_f32[0] = fovX_calc.m128_f32[0] * 0.5;
5 ucrtBase_Tanf();
6 fovY_calc = fovX_calc;
7 tanFovXby2_dup = fovX_calc.m128_f32[0];
8 fovY_calc.m128_f32[0] = fovX_calc.m128_f32[0] / *(float *)(a1 + 0x18);
9 ucrtBase_aTanf();
10 fovY_val = (__m128)*(unsigned int *)(a1 + 0x430);
11 fovX_val = fovX_calc;
12 fovX_val.m128_f32[0] = fovX_calc.m128_f32[0] * 2.0;
13 if ( fovY_val.m128_f32[0] == 0.0 )
14 {
15 ucrtBase_aTanf();
16 fovY_val = fovY_calc;
17 fovY_val.m128_f32[0] = fovY_calc.m128_f32[0] * 2.0;
18 }
19 fovX_val.m128_f32[0] = fovX_val.m128_f32[0] * 0.5;
20 ucrtBase_Tanf();
21 xScale = (__m128)0x3F800000u;
22 fovY_val.m128_f32[0] = fovY_val.m128_f32[0] * 0.5;
23 tan_fovX_half_saved = fovX_val;
24 xScale.m128_f32[0] = 1.0 / fovX_val.m128_f32[0];
25 ucrtBase_Tanf();
26 v39 = (__m128)*(unsigned int *)(a1 + 0x428);
27 v40 = (__m128 *)(a1 + 0xF0);
28 v41 = a1 + 0x130;
29 tan_fovY_half_save = fovY_val;
30 v43 = (__m128)0x3F800000u;
31 yScale = (__m128)0x3F800000u;
32 yScale.m128_f32[0] = 1.0 / fovY_val.m128_f32[0];
33 v45 = zNear;
34 v45.m128_f32[0] = zNear.m128_f32[0] - zFar.m128_f32[0];
35 anomaly_offset = (__m128)*(unsigned int *)(a1 + 0x42C);
36 *(__m128 *)(a1 + 0x100) = _mm_unpacklo_ps((__m128)0LL, _mm_unpacklo_ps(yScale, (__m128)0LL));
37 v43.m128_f32[0] = 1.0 / (float)(zNear.m128_f32[0] - zFar.m128_f32[0]);
38 *(__m128 *)(a1 + 0xF0) = _mm_unpacklo_ps(_mm_unpacklo_ps(xScale, (__m128)0LL), (__m128)0LL);
39 zFarByzNearNegzFar = v43;
40 zFarByzNearNegzFar.m128_f32[0] = v43.m128_f32[0] * zFar.m128_f32[0];
41 *(__m128 *)(a1 + 0x110) = _mm_unpacklo_ps(_mm_unpacklo_ps(v39, zFarByzNearNegzFar), _mm_unpacklo_ps(anomaly_offset, (__m128)0xBF800000));
42 zFar.m128_f32[0] = zFar.m128_f32[0] * zNear.m128_f32[0];
43 v48 = zFar;
44 v48.m128_f32[0] = zFar.m128_f32[0] * v43.m128_f32[0];
45 v45.m128_f32[0] = v45.m128_f32[0] / zFar.m128_f32[0];
46 row3_packed = _mm_unpacklo_ps(_mm_unpacklo_ps((__m128)0LL, v48), (__m128)0LL);
47 v50 = (__m128)0x3F800000u;
48 *(__m128 *)(a1 + 0x120) = row3_packed;
49 tan_fovY_half_save.m128_f32[0] = fovY_val.m128_f32[0] * *(float *)(a1 + 0x42C);
50 tan_fovX_half_save.m128_f32[0] = fovX_val.m128_f32[0] * *(float *)(a1 + 0x428);
51 v50.m128_f32[0] = 1.0 / zNear.m128_f32[0];
52 *(__m128 *)(a1 + 0x130) = _mm_unpacklo_ps(_mm_unpacklo_ps(fovX_val, (__m128)0LL), (__m128)0LL);
53 *(__m128 *)(a1 + 0x140) = _mm_unpacklo_ps((__m128)0LL, _mm_unpacklo_ps(fovY_val, (__m128)0LL));
54 *(__m128 *)(a1 + 0x150) = _mm_unpacklo_ps((__m128)0LL, _mm_unpacklo_ps((__m128)0LL, v45));
55 *(__m128 *)(a1 + 0x160) = _mm_unpacklo_ps(
_mm_unpacklo_ps(tan_fovX_half_save, (__m128)0xBF800000),
_mm_unpacklo_ps(tan_fovY_half_save, v50));
56 *(float *)(a1 + 0x1C) = 1.0 / fminf(tanFovXby2_dup, v34.m128_f32[0]);
57 }
Conclusion: Owning the Pipeline
And there we have it. We have successfully reverse-engineered the complete perspective and inverse projection matrix construction inside the Dunia Engine.
We are now free to Intercept, Modify and Read the matrices, We now control what the game can see.
A Trampoline hook here and we can control how the game engine goes from View -> Clip space.
Hopefully, this series has demystified the process and given you the tools to tackle your own reverse engineering targets. The math might look intimidating at first, but at the CPU
level, it all breaks down to logic, patterns, and proving your hypotheses.
Happy reversing!