Part 5.2: Reversing Construction of the Projection Matrix (Depth Mapping)
Depth Calculation:
We’ve got the xScale and yScale calculations sorted, now it’s time to see how they calculate Depth Mapping, the values at [2][2] and [3][2].
Row 2:
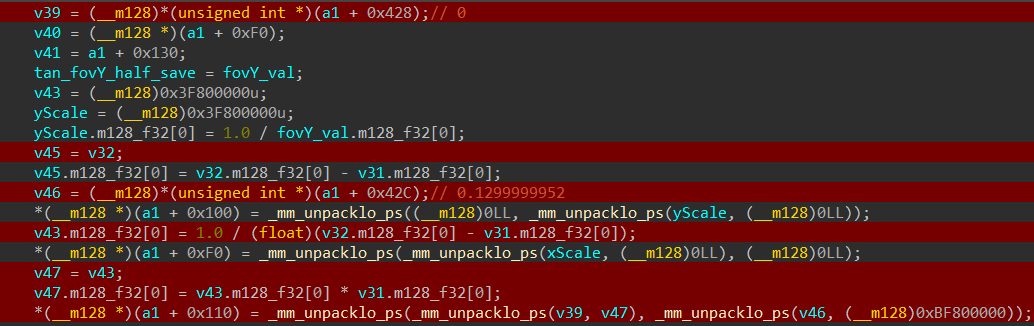
We will isolate all things related to row 2 (yes, 2… we are counting rows from 0).
Let’s start with these lines:
The first line seems to just load a zero from memory but the second line is interesting…
Since we’ve never seen what “v35” holds let’s trace back to where it gets it value from.
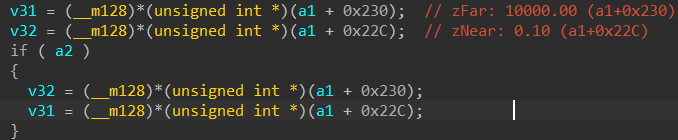
Notice the if (a2) block: it conditionally swaps zNear and zFar. This seems to be a case of Standard Depth projection VS Reverse-Z projection.
Since my testing shows the if block does not execute, the engine is defaulting to a standard depth mapping. For the sake of this walkthrough, we will proceed with the unswapped
variables: v31 as zFar and v32 as zNear
Now I will rename the variables “v31” and “v32” as zFar and zNear respectively.
So now:
The Anomaly / Asymmetric offset
Let’s just get the anomaly out of the room now itself:
Through dynamic analysis we see it’s loading a constant value of “0.1299999952” and further down the line it gets placed at “[2][1]” slot of the projection matrix. This seems to be responsible for some kind of Asymmetric / Off-Center Frustum construction.
How about we just test this theory right now? Let’s try to remove the “0.13” constant from the Projection matrix and see how it would affect the render in-game.
Let’s do so in cheat engine by doing a trampoline hook.
original instruction:
movss xmm3,[rbx+0000042C]
our jmp:
jmp codeCave
nop
Code Cave:
xorps xmm3, xmm3
jmp back
Here is a comparison in game with the anomaly factor enabled versus nullified

This pretty much confirms that this is an intentional asymmetric offset.
Let’s now continue with depth mapping calculations.
Starting with this block:
This is really self-explanatory…
v43 = 1 / zNear - zFar
Then:
v47 = v43 * zFar
Putting it all together we get:
\[\large v_{47} = \frac{z_{far}}{z_{near} - z_{far}}\]I will now rename “v47” to “zFarByzNearNegzFar”.
Next is Row3!
Row3:
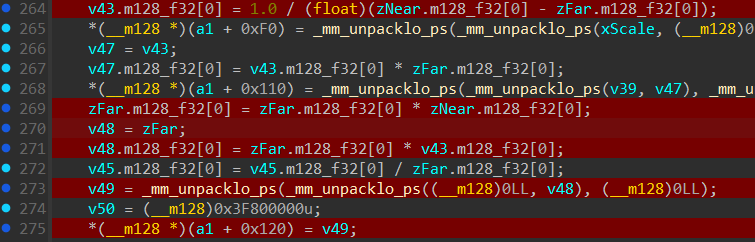
Taking this block:
The first line for v43 is 1 / zNear - zFar
But in the next line the value inside zFar Changes to zFar * zNear
Then it’s simply: v48 = zFar(zFar*zNear) * v43
putting it all together its:
\[\large v_{48} = \frac{z_{far} \cdot z_{near}}{z_{near} - z_{far}}\]Putting it all into the Projection Matrix:
Let’s isolate all lines which store the Projection Matrix into the Camera Structure:
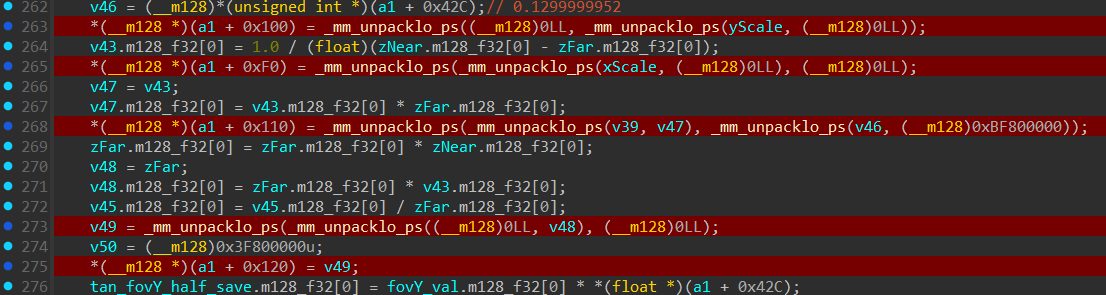
Row 0:
Let’s see what’s happening here line by line:
This is what mm_unpacklo_ps does: But what the hell is an _mm_unpacklo_ps??
Let’s go through what mm_unpacklo_ps does in this line:
going through the inner unpack first
the xScale variable has 4 floats and only the lowest float is the “xScale” rest is zero, so:
xScale: x = 1/tan(fovX/2), y = 0, z = 0, w = 0
then (__m128)0LL just means a m128 variable with all floats set to 0.
unpacking this we get:
Result = [1/tan(fovX/2), 0, 0, 0]
After this it does one more unpacklo
Doing this we again get:
Result = [1/tan(fovX/2), 0, 0, 0]
so you really only needed 1 mm_unpacklo_ps…
Then it simply stores it as “ROW 0” of the Projection matrix inside the camera structure “(a1+0xF0)”.
Since mm_unpacklo_ps is a pretty straightforward instruction I will not be babysitting by showing each unpack every single row, here are the lines and the result:
Row 1:
Result: [0, tan(fovY/2), 0, 0]
Row 2
Alright let’s slow down here a bit:
here “v39” comes from:
which seems to just be zero.
v46 is the “0.1299999952” constant we’ve seen before and “0xBF800000” is hex for “-1.f”
unpacking all this we get:
Result: [0, 0.13, Far / (Near-Far), -1]
Row 3:
v48 is far*near/Near-far
Result: [0, 0, (far*near) / (Near-far), 0]
Putting the code together:
Final Layout:
Now we have finally reverse engineered how the game constructs the Perspective-Projection Matrix per frame with it’s layout being:
\[\begin{bmatrix} \frac{1}{\tan(fovX/2)} & 0 & 0 & 0 \\ 0 & \frac{1}{\tan(fovY/2)} & 0 & 0 \\ 0 & 0.13 & \frac{Far}{Near - Far} & -1 \\ 0 & 0 & \frac{far \cdot near}{Near - far} & 0 \end{bmatrix}\]Stored at: a1 + 0xF0 to a1 + 0x130 with a1 being the Camera Structure
The Payoff: Owning the Camera
Because we don’t just know what the projection matrix is, we know exactly how it gets built, instruction by instruction. And in reverse engineering, understanding construction means you have the power of interception. We are no longer limited to what the game developers expose in the settings menu; we can force the engine to render however we want.
By hooking this function and manipulating the registers before the final _mm_unpacklo_ps calls, we open the door to massive engine modifications!
I already talked about what we could do with accesses to the projection matrix construction: What’s the point of doing this?
Next up, we tackle the Inverse Projection Matrix.